Three layout scenarios: Abstract Geometric, Urban Architectural, and Indoor Scene.
Abstract
Humans can effortlessly perceive spatial layouts, form cognitive representations, reason about spatial relations, and translate such reasoning into actions in everyday 3D environments. Although recent vision-language models have shown promising performance on observation-conditioned spatial perception and reasoning tasks, it remains unclear whether they can build coherent spatial understanding, act upon it, and refine their actions through multi-turn feedback. To study this problem, we introduce SpatialAct, a simulator-grounded benchmark for probing action-conditioned spatial reasoning in 3D scenes. Starting from the most challenging setting, Multi-turn Interactive Refinement, we further design its decomposed counterpart, Single-step Error Detection and Fix, together with five fundamental spatial ability tasks to diagnose the underlying causes of model failures. Experiments reveal a clear reasoning-to-action gap: current VLMs can perform well on isolated spatial reasoning tasks, but struggle to maintain coherent spatial beliefs and produce reliable actions during multi-turn feedback, substantially underperforming humans.
Benchmark
SpatialAct evaluates whether VLM agents can move from passive spatial understanding to high-level simulator-executable actions. It covers abstract geometric, urban architectural, and indoor scenes, with paired top-view and isometric-view renderings and dynamically injected spatial errors.
Questions span open-ended, multiple-choice, and interactive feedback formats.
Basic abilities, single-step error detection and fix, and multi-turn refinement.
Proprietary and open-source models are compared with a human baseline.
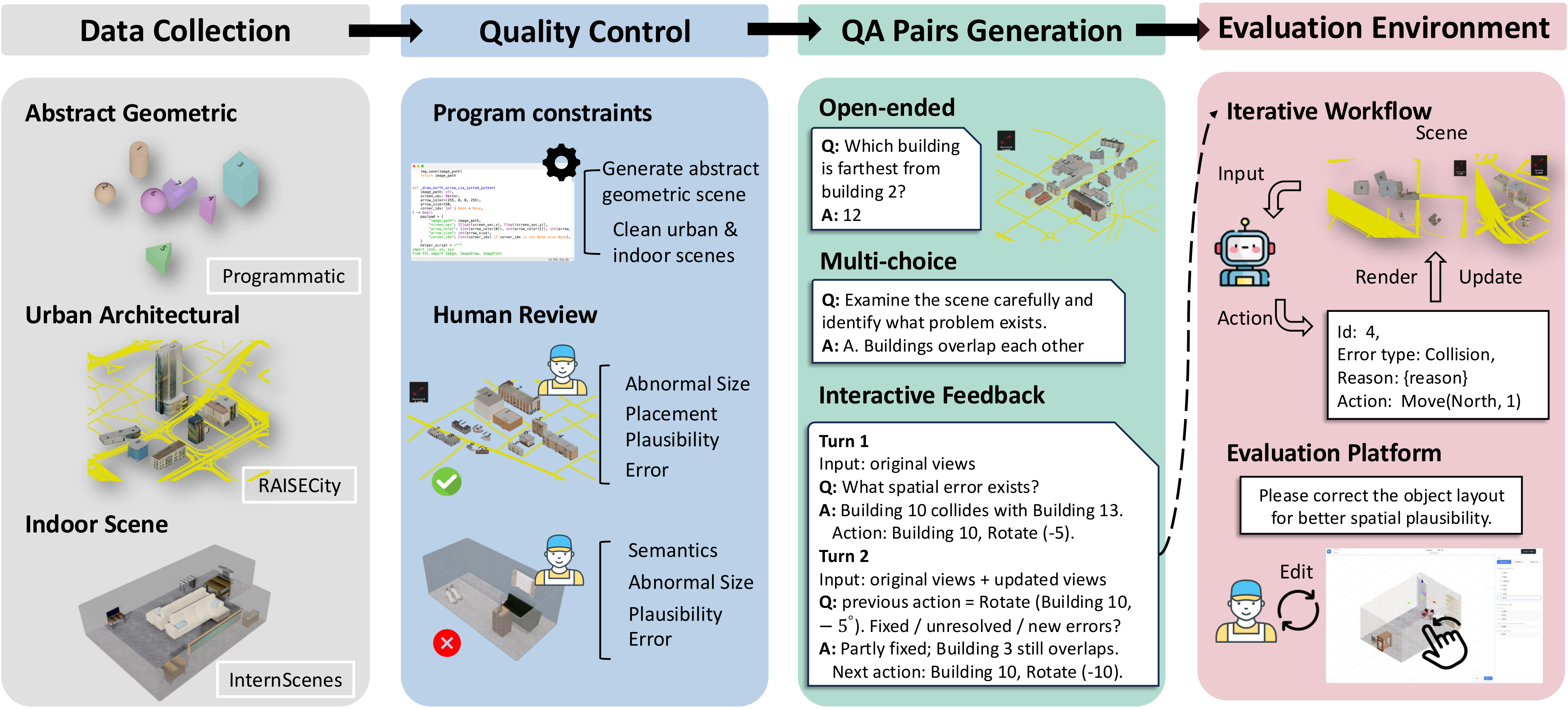
Benchmark construction pipeline
SpatialAct builds a scene-level benchmark through data collection, quality control, QA pair generation, and evaluation environment setup. Abstract Geometric layouts are procedurally generated, while Urban Architectural and Indoor Scene layouts are drawn from existing 3D scene sources and then cleaned, reviewed, and checked for spatial plausibility. Each scene is represented by paired top-view and isometric-view renderings, giving models complementary spatial evidence. The resulting QA pairs cover open-ended questions, multiple-choice diagnosis, and multi-turn feedback-based interaction.
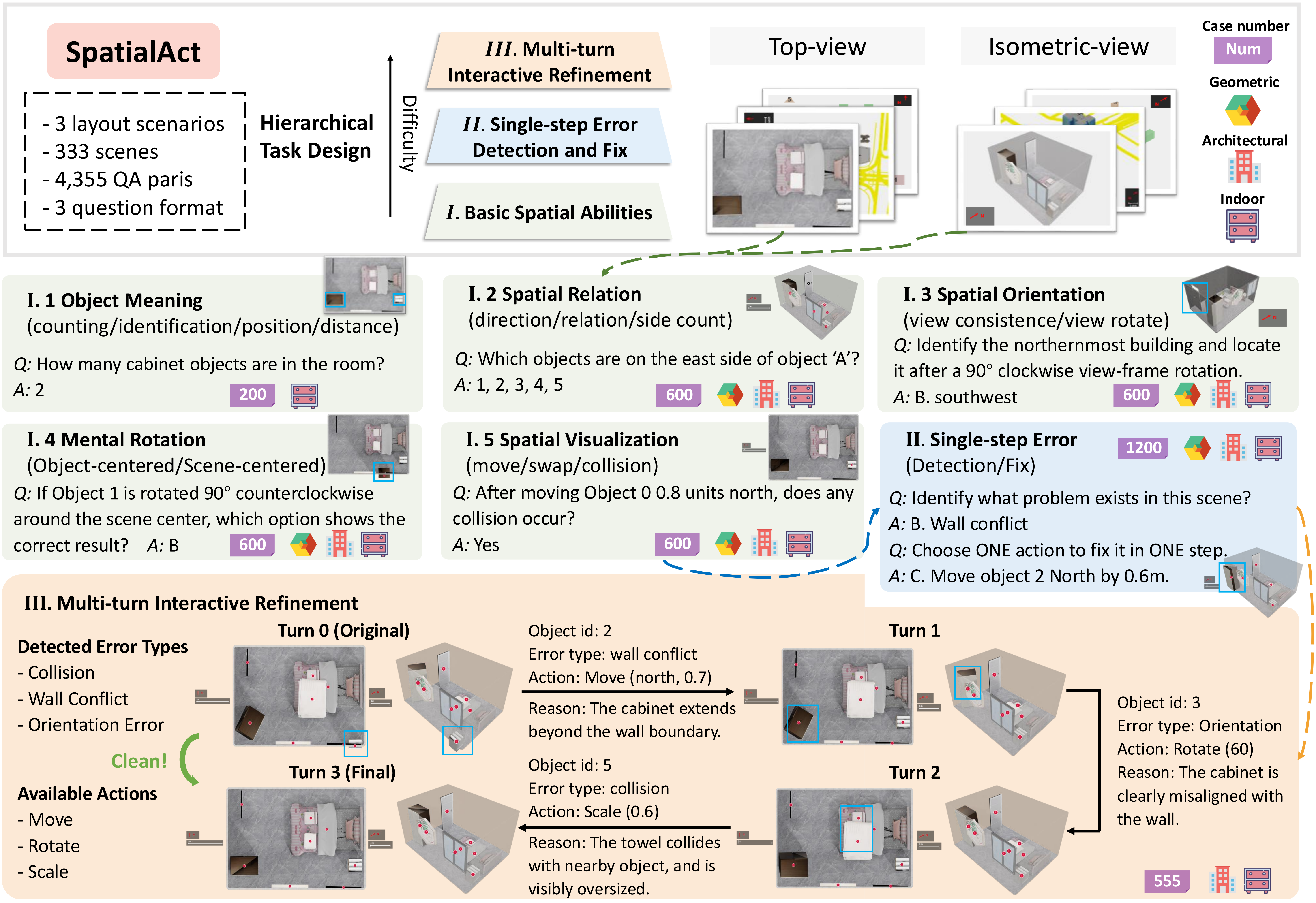
Task Design
Seven diagnostic tasks organized into
three levels.
Object Meaning
Spatial Relation
Spatial Orientation
Mental Rotation
Spatial Visualization
Single-step Error Detection and Fix
Multi-turn Interactive Refinement
Human Evaluation Environment
In Multi-turn Interactive Refinement, each turn begins with top-view and isometric-view renderings of the current scene. The model diagnoses spatial errors, outputs corrective commands, and receives updated views after simulator execution.
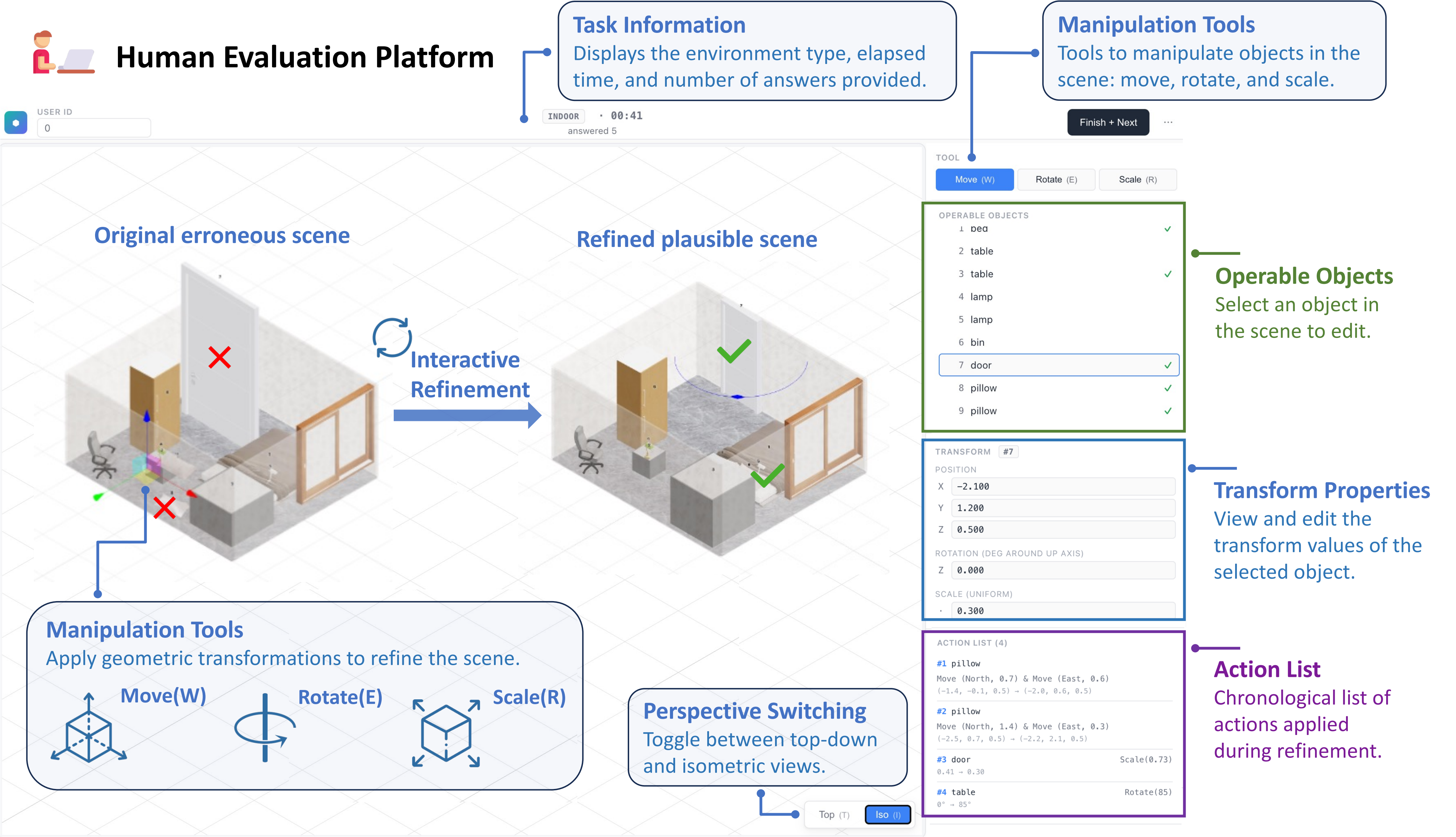
Human participants refine scenes through a web-based interface with object selection, transform controls, perspective switching, and an action history. This interface provides the human baseline for the same multi-turn interactive refinement setting used to test VLM agents.
Metrics
Metrics for reliable spatial action
SpatialAct reports accuracy for static diagnostic tasks and five complementary metrics for multi-turn interactive refinement, covering repair quality, completion, efficiency, stopping behavior, and reasoning cost.
Accuracy
Used for Basic Spatial Abilities and Single-step Error Detection and Fix.
Repair Rate
Measures how effectively a model reduces abnormal spatial errors.
Scene Success Rate
Measures whether all errors are fully resolved at the scene level.
Effective Repair Turn Ratio
Measures how often interaction turns actually improve the scene.
Premature Stop Ratio
Measures how often a model stops while unresolved spatial errors remain.
Avg. Completion Tokens
Measures the reasoning cost accumulated across interaction turns.
Results
Put the figures you want to browse into
assets/images/, then add them to assets/figures.js.
Multi-turn Case
Citation
Tianhui Liu, Jie Feng, Zhiheng Zheng, Shengyuan Wang, Yiming Guo, Yanxin Xi, Hangyu Fan, Yong Li, and Pan Hui. SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes. arXiv preprint arXiv:2605.31148, 2026.
@article{liu2026spatialact,
title={SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes},
author={Liu, Tianhui and Feng, Jie and Zheng, Zhiheng and Wang, Shengyuan and Guo, Yiming and Xi, Yanxin and Fan, Hangyu and Li, Yong and Hui, Pan},
journal={arXiv preprint arXiv:2605.31148},
year={2026}
}